
「译」硬核到极致的 Event Loop 讲解,不信你看完还不会!
「译」硬核到极致的 Event Loop 讲解,不信你看完还不会!
事件循环 (Event Loop) 是一个我以为懂了, 但直到最近才发现自己什么都不懂的概念.
会发现这件事,是因为我在研究 React Fiber 的过程中, 得知了一个能提升网页性能的 API requestIdleCallback, 它的回调(callback) 会在浏览器空闲(Idle)时执行,其中一个时机点是帧尾.
问题来了, 什么是 帧尾 ?, 要回答这个问题,首先当然要知道什么是帧(frame). 原本我以为, 帧 就等同于网页画面更新—-每一帧, 画面就更新一次.但若是这样,哪来的尾 可以给requestIdleCallback执行? 或许,一帧除了更新,还做了许多事.
就这样, 我从想了解一帧究竟做了哪些事,不小心掉进事件循环的漩涡, 纠缠了一个多礼拜才爬出来,又花了好几天才凝练成这篇文章.
本文将从官方规范入手, 看完它,你便能回答:
- 事件循环的运作流程如何?
- 帧 是什么?
- setTimeout, requestAnimationFrame, requestIdleCallback, 分别发生在事件循环的哪个阶段
- 宏任务 (macrotask) 和微任务 (microtask) 是什么? 它们与事件循环的关系是什么?
- 每轮事件循环都会更新页面吗?
- JavaScript 是单线程(single threaded)的, 但却能发出 HTTP 请求而不阻塞(non-blocking), 这是怎么办到的?
JS 执行却不阻塞的秘密
在开始之前,先来看一张图:
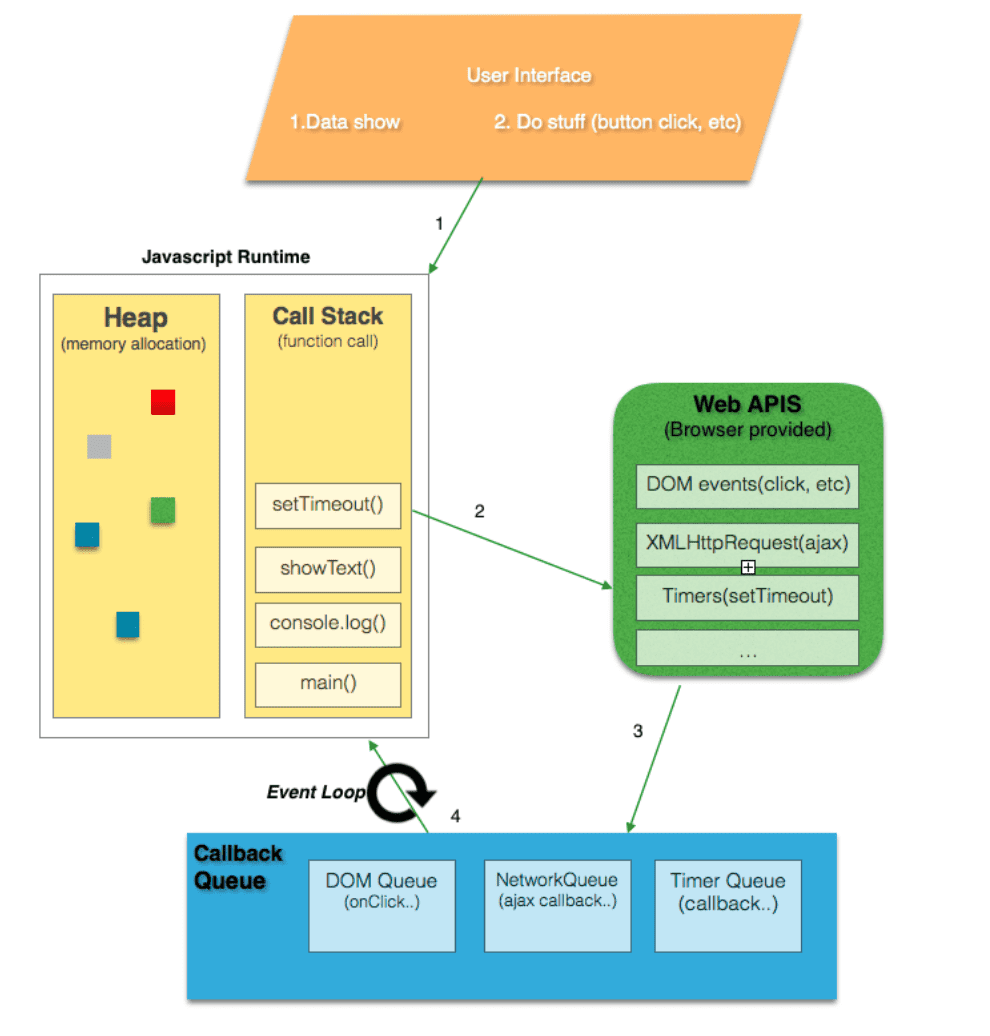
事件循环在浏览器的角色, 图片来源以不可考.
不用看太久,有个概念就好,等你读完这篇文章,,就能看懂这张图了.
首先要声明,事件循环与 JS 的执行(runtime)环境相关, 它与 JS 引擎本身无关. 常见的运行环境还有: 浏览器,Node.js, 每种运行环境可能都有自己实现事件循环的方式,而本文只探讨浏览器的事件循环(Node.js 的事件循环也是一个重要的主题,等哪天我搞懂了再来写).
为什么需要事件循环? 这与 JS 单次执行(单线程, 译者注.)的特性有关. 单次执行意味着 JS 一次只能执行一段程序,当 JS 在调用(invoke)一个函数时, 没有任何其他程序可以同时执行, 除非这个函数结束或者被中断(suspended), (后者可用 generator [^1]实现).
深入点说, JS 内部有一个栈(call stack), 称为上下文执行栈(execution context stack), 这个栈是用来追踪所调用的函数的. 每当程序调用一个函数,这个函数所产生的执行上下文便会被压入(push)栈; 当这个函数执行完毕,便会被弹出(pop). 函数的执行顺序遵循后入先出 (LIFO, Last In First Out)的模式.
单次执行虽然简单易懂,但却有一个明显的问题: 假如一个函数执行过久,便会卡住之后函数的执行. 如果这些函数恰好是与 UI Rendering 相关的事,那画面便会延迟更新,这对使用体验来说是致命的.
现在让我们来想一下,JS 有什么操作是相当耗时的? 无论你的答案是什么,我都已经想好了,那就是请求.在AJAX[^2] 大行其道的年代,大家都在用XMLHTTPRequest(XHR)[^3] 请求来请求去. 如果使用者网速特别慢,可能一次请求要花费好几秒,但为什么使用者的网页仍能正常渲染(render), 而没有丝毫延迟?
因为 XHR 并非由 JS 本身, 而是由它的运行环境(即浏览器)自身的执行来处理的,因此不会阻塞调用栈. 有浏览器负责处理的函数还有计时器setTimeout, 与动画紧密相关的requestAnimationFrame, 害我一脚踏入事件循环泥沼的requestIdleCallback… 它们统称为Web APIs[^4].
以计时器来举例,当 JS 引擎执行到setTimeout(func, 3000), 浏览器便接过计时器的操作,等 3 秒一到,便将它的func回调压入上下文执行栈,让引擎执行. 这可以说事一种非同步(asynchronous)的机制.
一个复杂的网页,可能会有许多回调要执行,现在让我们来问: 是谁不停取出回调,并将回调压入上下文执行栈的?
那就是今天的主角: 事件循环.
事件循环的基本概念
同样,在进入到事件循环的流程前,先来看一张图:
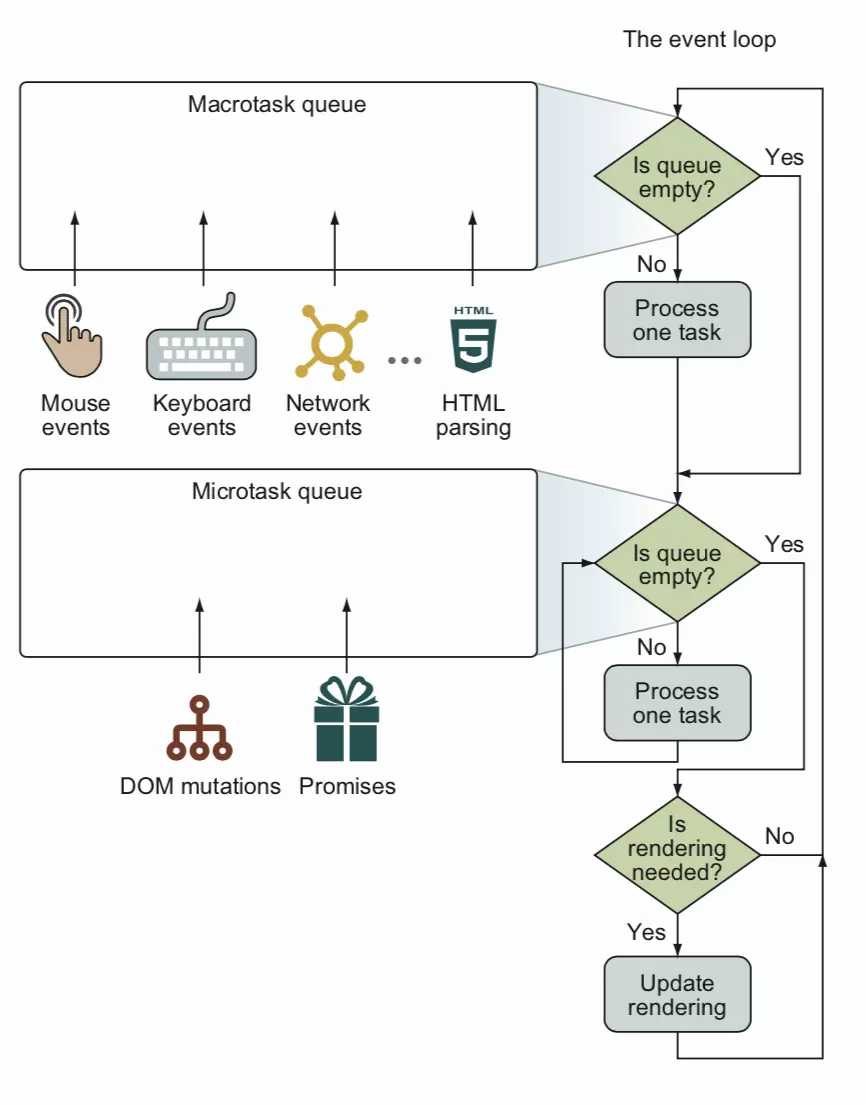
事件循环的运行流程. 图片来源已不可考.
接下来,完美会跟着这份WHATWG(Web Hypertext Application Technology Working Group)[^5]社群(a.k.a. 浏览器大佬)编写的HTML 规范文件 [^6], 来理解事件循环详细的运行流程.
为什么需要事件循环? 开宗明义,规范便说了:
为了协调事件,用户交互,脚本,渲染和网络活动等, 用户代理 user agents[^7]必须使用本节所描述的事件循环. 每个代理都有一个相关联且唯一的事件循环.
接下来,规范根据不同代理对事件循环做了三种分类: window event loop、worker event loop、worklet event loop.
第一个代理是我们最常碰到的window(浏览器环境,译者注);第二个代理告诉我们service worker[^8] 会有自己的事件循环;第三个代理我不知道是什么,worklet[^9]似乎是一个实验性 API。
让我们往下滑:
一个事件循环会有一个到多个任务队列(task queues)。
每个任务任务(task)都来自特定的任务源(task source)。每个任务源都必须对应一个特定的任务队列。
这两段话出现了三个专有名词:任务,任务源,任务队列。
首先,任务就是宏任务,它可以干的事相当多,包括发布(dispatch)Event 事件[^10],(想想当事件监听器触发时,回调函数拿到的第一个参数)、解析(parse)HTML、调用回调、请求fetch[^11]资源、响应(reacting)DOM 操作。
任务源也很多,但大都被归类为以下四种[^12]:
- DOM 操作: 比如以非阻塞的方式将元素插入 document。
- 用户交互: 比如键盘输入或者鼠标滑动。
- 网络活动
- 访问历史记录(history traversal):比如调用
history.back()API。
那任务队列干嘛的呢?它是拿来分类任务源用的;换言之,不用的任务源可能会被塞进同一个任务队列。但为什么要对任务源进一步分类?这个例子说明的很清楚:
例如,用户代理可以将任务队列分为给鼠标和键盘事件(即用户交互任务源)用的,和给其它任务源用的。籍此,用户代理可以在事件循环的处理模型[^13]的初始步骤中,给与用户交互任务源关联的任务队列四分之三的优先处理权,以让界面保持响应性,但又不会卡住其它任务队列。
换言之,说到任务的处理顺序时,并没有谁先触发谁就先执行的道理,这一切都要看你的浏览器如何实现。
最后再讲一件事:
微任务队列(microtask queue)不是任务队列。
微任务队列是一种通俗的讲法,指的是通过queue a microtask[^14]算法创建的任务。
微任务虽是一种任务(它们具有相同的结构[^15]),但它所形成的队列与任务队列不同,而这是因为它们所使用的算法不同。
有了这些基本概念,接下来,让我们直接进入到事件循环的重头戏吧!
事件循环是怎么运作的?
在8.1.6.3 处理模型(Processing model[^16]中,规范描述了事件循环的运作流程:
只要事件循环存在,便必须一直运行以下步骤:
- 挑出一个任务队列,要怎么挑由用户代理决定[^17]。如果没有任务队列,那就直接跳到微任务队列步骤。
- 将oldestTask设为该任务队列中的第一个任务,并移除。
- 将当前正在进行的任务[^18]设为oldestTask。
- 将 taskStartTime 设为 current high resolution time[^19]。
- 执行oldestTaks’s steps[^20]
- 将当前正在运行的任务设为 null。
前六步都满好理解的。
1: 「由用户代理决定」符合我们前面所说的,用户代理可自行决定要给哪个任务队列较高的优先处理权。
2: 由于是任务队列,当然是遵循先进先出(FIFO,First-In-First-Out)的原则。
微任务:执行微任务检查[^21]。
a. 将 oldestMicrotask 设为对微任务队列出队 dequeue[^26]的结果。
b. 将当前正在运行的任务设为 oldestMicrotask 。
c. 运行 oldestMicrotask 。
d. 将当前正在运行的任务设为 null 。
e. 如果 event loop[^22]’s performing a microtask checkpoint[^23] 为 true, 返回。
f. 设置 event loop[^24]’s performing a microtask checkpoint[^25] 为 true 。
g. 只要微任务队列不为空:
h. For Each environment settings object[^27] whose responsible event loop[^28] is this event loop[^29] ,
notify about rejected promises[^30] on that environment settings object[^31] .
i. Cleanup Indexed Database transactions[^32]
j. 执行 ClearKeptObjects[^33]
k. 设置event loop[^34]’s performing a microtask checkpoint[^35] 为 false 。
7:开始处理微任务。 首先检查 performing a microtask checkpoint 这个标志 (flag)。为什么需要?因为微任务检查并不是只有在事件循环的这个时机才触发,其它触发时机比如调用回调后;而为了避免在处理微任务队列时重复执行微任务检查(这可能在 7.3.3发生),因此需要一个标识来控制(后面会再详细说明微任务的执行策略)。
7.3:检查微任务队列是否为空,若不为空,便执行第一个微任务。重复这个过程,直到所有微任务都执行完毕。
将 hasARenderingOpportunity 设为 false。
将 now 设为 current high resolution time[^37].[HRT[^38]]
Report the task[^39]’s duration by performing the following steps:
- Let top-level browsing contexts be an empty set[^40].
- For each environment settings object[^41] settings of oldestTask’s script evaluation environment settings object set[^42], append[^43] setting’s top-level browsing context[^44] to top-level browsing contexts.
- Report long tasks[^45], passing in taskStartTime, now (the end time of the task), top-level browsing contexts, and oldestTask.
8: 从字面上理解,hasARenderingOpportunity便是「是否有机会渲染」,一开始是 false,它将跟等下第 10 步的更新页面(Update The rendering)有关。
9:这里的 now 将成为 requestAnimationFrame 回调的第一个参数。
10:我看不太懂在干嘛,但 10.3 回调的 long task 似乎会出现在 Chrome 开发者工具 Performance[^46] 面板中。
更新页面:如果是 window Event Loop,则:
- 任何 Document 对象 B,其browsing context[^49] 的 包含Document(container document[^50])对象为 A,则,B 必须在 A 后插入列表。
- If there are two documents A and B whose browsing contexts[^51] are both child browsing contexts[^52] whose container documents[^53] are another
DocumentC, then the order of A and B in the list must match the shadow-including tree order[^54] of their respective browsing context containers[^55] in C’s node tree[^56].
Let docs be all
Documentobjects whose relevant agent[^47]’s event loop[^48] is this event loop, sorted arbitrarily except that the following conditions must be met:In the steps below that iterate over docs, each
Documentmust be processed in the order it is found in the list.渲染機會(Rendering opportunities):移除浏览器上下文(browsing context)[^57]沒有渲染机会的 docs。
11: 这一步做的事情相当多(上面一小部分),主要是处理和页面渲染相关的事。
11.1:我没有全部看懂,但大致就是选出Document,将它们指定给docs,并以一定的规则排序。
11.2:你可能会疑惑,要怎么决定有没有渲染机会?
如果用户代理当前能够将浏览器上下文的内容呈现给与用户,那该浏览器上下文就有渲染机会,这需要考虑硬件刷新频率的限制,和用户代理处于性能考量的节流,也需要考虑内容的可呈现性(presentable),即使它在视口(viewport)外。
规范似乎觉得这里没说清楚,于是又补上一句:
浏览器上下文的渲染机会是基于硬件限制(如显示器刷新率(display refresh rates))和其他因素(如页面性能或页面是否在背景(background)来确定的)。渲染机会通常会定期出现。
好像还是没说清楚,再给一个注解:
本规范并没有规定任何特定的模式来选择渲染机会。但距离说,若浏览器试图实现 60 Hz 的刷新率,那渲染机会最多每 1/60 秒要出现一次(约 16.7ms)。若浏览器发现某个浏览器上下文无法维持这个速率,它可能会将渲染机会降到可持续的每秒 30 次,而不是偶尔掉帧。同样,如果一个浏览器上下文不可见,用户代理可能会决定将该页面降到每秒 4 次渲染机会,甚至更少。
说了这么多,我们大致上可以这么总结:不是每轮事件循环都会更新页面,其频率高低,看浏览器怎么实现。
- 更新页面:
- 用户代理认为更新 document 的浏览器上下文的页面不会有明显的(visible)效果。
- document 的 map of animation frame callbacks 为空。
- 如果 docs 不为空,则将hasARenderingOpportunity 设为 true。
- 不必要的渲染(Unnecessary rendering):移除满足以下条件的 docs:
- 移除用户代理由于其他原因认为最好(preferrable)跳过更新页面的 docs。
11.3:hasARenderingOpportunity 在第 8 步出现过。
11.4-5: 与 11.2 做的事类似,再次数筛选掉不需要渲染的docs。
11.4: 把筛选条件说的很清楚,值得注意的是,animation frame callback 就是放在 requestAnimationFrame 的回调。
11.5: 等于没说,其目的应该是授予浏览器决定是否要渲染的权利。不过规范还是举例了:
比如为了确保某些任务紧接着执行,只有把微任务检查交错其中(而且没有 animation frame callback参与)。具体来说,用户代理可能希望合并定时器回调,中间没有页面更新。
同时,规范也说明了设立 11.2 和 11.4 的目的:
被标注为「渲染机会」的步骤可防止用户代理在 无法向用户呈现新内容时 更新页面。
被标注为『不必要的渲染』的步骤可防止用户代理在 没有新内容可绘制时 更新页面。
到这里,如果 docs还有充分活跃(fully active)[^58]的document 那就一一对它们执行:
- 更新页面:
- flush autofocus candidates[^59]
- run the resize steps[^60]
- run the scroll steps[^61]
- evaluate media queries and report changes[^62]
- update animations and send events[^63]
- run the fullscreen steps[^64]
- run the animation frame callbacks[^65]
- run the update intersection observations steps[^66]
- Invoke the mark paint timing[^67] algorithm
- 更新该 Document的页面,及其浏览器上下文以反映当前状态
11.6-13:你可以看到很多熟悉的名字,比如事件类型 resize 和 scroll、与 RWD(Responsive Web Design)息息相关的media query、常被用来做懒加载的 IntersectionObserver[^68]
11.12 执行 requestAnimationFrame 的回调。
11.14: 不知道在干嘛,但似乎跟网页性能指标 FCP (First Contentful Paint)[^69]。
到这里,事件循环的更新页面结束,接下来:
如果满足如下条件:
运行 start an idle period algorithm[^70]
a. 事件循环还是 window Event Loop;
b. 在任务队列中没有任何任务;
c. 微任务队列为空;
d. hasARenderingOpportunity 为 false;
12:若条件都满足, requestIdleCallback 的回调将在这步执行。
第 13 不是在讲还是 worker Event Loop 的情况,与本文主体无关,跳过。
一轮事件循环到此运行完毕。现在再回去看看本节开头的流程图,是不是很清楚了呢?
还不清楚?没关系,让我们结合调用栈、web APIs 和事件循环,来实际跑一遍流程吧!
从规范了解事件循环
先来看一个简单的例子
1 | setTimeout(function onTimeout() { |
当程序执行时,会发生什么?
- 建立全局执行上下文(global execution context),压入调用栈。
- 遇到 setTimeout, 由 Web API 接管计时器的处理,时间一到,便把 onTimeout 排入任务队列。
- 遇到 Promise.then, 将 onFulfill 排入微任务队列。
- 在控制台打印 main。
- 调用 logSomething,将其函数执行上下文压入调用栈。
- 答应出 something。
- logSomething 执行完毕,弹出。
- 程序执行完毕,全局执行上下文弹出。
- 执行微任务检查:微任务队列不为空,出列。
- 调用 onFulfill, 将其函数执行上下文压入调用栈。
- 打印 promise1。
- onFulfill 执行完毕,弹出。
- 遇到 Promise。then, 将onFulfill 排入微任务队列。
- 微任务队列不为空,出列。
- 调用 onFulfill, 将其函数执行上下文压入调用栈。
- 打印 promise2。
- onFulFill 执行完毕,弹出。
- 微任务队列为空,微任务队列检查完毕。
- 调用栈为空,事件循环从任务队列最旧的任务。
- 调用onTimeout,将其函数执行上下文压入调用栈。
- 打印 timeout。
- onTimeout 执行完毕,弹出。
你可能会比较疑惑:为什么微任务是在程序执行完毕后便执行?微任务检查不是应该在调用一个任务后(在此例即是 onTimeout)才出发吗?
别忘记我提醒过你的:微任务检查的触发时机相当多。下一节(微任务的执行策略)我会详述微任务执行策略。
再来看一个比较复杂的例子:
HTML:
1 | <button id="btn" type="button">Click me!</button> |
Js:
1 | var btn = document.getElementById('btn') |
当你点击按钮,控制台会打印出什么?
答案不止一种,在不同浏览器或同一浏览器的不同时间,可能会出现不同的结果。若只看最常出现的结果,
1 | promise1 |
无论哪种结果,都能被事件循环的处理模型解释。换言之,差异并不来自规范失效,而来自规范赋予浏览器的弹性。
让我们一步步来:
click事件已有 Web API 接收处理,将其回调加入任务队列。- 调用
onClick,将其函数执行上下文压入执行栈。 - 遇到
setTimeout,有 Web API 接管计时器的处理,时间一到便把onTimeout, 加入任务队列。 - 遇到
Promise.then(), 将onFulfiil加入微任务队列。 - 遇到
requestAnimationFrame,将其回调onRaf放入 map of animation frame callbacks。 - 遇到
requestIdleCallback, 将其回调OnIdle1放入 list of idle request callbacks。 onClick执行完毕,弹出。- 执行微任务检查:微任务队列不为空,出列。
- 调用
onFulfill, 将其函数执行上下文压入执行栈。 - 打印出
promise1. onFulfill执行完毕,弹出。
接下来,分歧产生了:究竟是会先执行计时器的回调 onTimeout, 还是 requestAnimationFrame的回调 onRaf ?
而此时 onTimeout有没有被加入任务队列?你可能会说, setTimeout的等待时间是 0, 其回调应该就要被马上加入任务队列吧?
不一定的,因为规范在计时器初始化步骤[^71]中其实有授予浏览器延长时间的权利:
- 可选择再等待一个由用户代理决定的时间长度。
目的是:
为了优化(optimize) 设备的用电情况(power usage).例如,一些处理器具有低电量模式,其中定时器的粒度(granularity)会降低。在这种平台上,用户代理可减慢定时器,而非要求处理器使用更精确的模式、消耗更高的电量。
所以,Chrome 的情况是:
- 调用栈为空,由于无合格的任务队列,且微任务队列为空,事件循环进到更新页面步骤。
- 运行
animation frame callbacks。 - 调用
onRaf,将其函数执行上下文压入调用栈。 - 打印
raf. - 遇到
Promise.then(),将onFulfill2加入微任务对列。 onRaf执行完毕,弹出。- 执行微任务队列检查:微任务队列不为空,出列。
- 调用
onFulfill2,将其函数执行上下文压入调用栈。 - 打印
promise2。 onFulfill2执行完毕,弹出。- 由于 hasARenderingOpportunity 为 true,或任务队列中有任务,跳过 start an idle period algorithm。
- 调用栈为空,事件循环从任务队列中取出最久的任务。
- 调用
onTimeout, 将其函数执行上下文压入调用栈。 - 打印
timeout。 - 遇到
requestIdleCallback,将其回调onIdle2放入 list of idle request callbacks。 onTimeout执行完毕,弹出。start an idle period algorithm, 调用onIdle1, 将其函数执行上下文压入调用栈。- 打印
idle1。 onIdle1执行完毕,弹出。- 调用
onIdle2,将其函数执行上下文压入调用栈。 - 打印
idle2。 onIdle2执行完毕,弹出。
微任务的执行策略
微任务的触发事件既简单又复杂。先讲复杂的:前面是说过,执行微任务前会先执行微任务检查,而微任务检查的触发时机可参考这张图:
 Image
Image
规范中有引用到 perform a microtack checkpoint关键字的段落。图摘自 WHATWG 规范文件[^72]
点击这个链接[^73],再点击 perform a microtack checkpoint粗体字,你也可以看到引用这个关键字的其他段落(当然不止这些,比如还有update animation and send events[^74])。
比较常见的触发点是 8.1.4.4的 Calling scripts,它在 clean up after running script的最后[^75],当调用栈为空,会执行微任务检查。
我没有很了解 script 在规范中的意义为何,只知道在很多地方都会执行 clean up after running script,最常见的便是 调用回调的 return 阶段的第 2 步[^76],而这就是为什么在上一节第二个例子中的 onRaf会在执行完毕后,马上执行微任务检查。
「太琐碎了吧!我怎么可能记得住?」在你喊出这句话之前,我要来讲一个简单的判断方法:只要当前调用栈为空,微任务检查便会立即执行;简而言之,微任务的执行策略是:见缝插针,尽可能早。
这个判断方法并没有在规范中明确表述(至少我没有找到),但它应能适用 99.9%的情景,剩下 0.1%还有待你分享给我。
只讲一个证据:现代浏览器已把 Promise.then(),看作是一种微任务(至少在 2015 年前不是如此,详情可见这篇文章[^77])。
而在 ECMAScript 规范里,有一个与微任务相似的概念,叫做 job,而 [Promise.then() 便是一种 job](https://262.ecma-international.org/11.0/#sec-promise-jobs*[79]job 的執行時機: https://262.ecma-international.org/11.0/#sec-jobs)[^78] 。因此,微任务的执行策略理论上要跟job*相容。对于 job 的执行时机[^79] 。你会发现它跟我前述的判断方法时一样的:
在未来的某个时间点,当没有正在运行的执行上下文,且执行上下文堆栈为空时。
(除了 Promise, MutationObserver[^80],queueMicrotask[^81])。有很多文章把 postMessage[^82],也当做微任务,但它其实是宏任务[^83]
来自 posted message 任务源
回答开头的问题:
帧是什么?帧是组成浏览器页面的基本元素:每个时刻的页面,都是由一个相同或不同的帧所组成的。想了解这句话的具体含义,可查看 Chrome 开发者工具 Performance 面板的 Frames 截图[^84 ] 。
帧与页面更新相关,但并不等同于页面更新。帧包括事件循环、布局(layout)、绘制(paint)等等。一帧就代表一次页面更新,但并不代表只有一轮事件循环,因为浏览器能根据各种原因跳过页面更行。
形象化的说,若浏览器是「人」,那帧就是『一天』这个时间单位——人的一生是由一天又一天组成的,就像浏览器页面是由一帧又一帧所组成的;人每天都会有固定的行程,且有一定顺序,比如睡觉,吃饭,上厕所,洗澡等等,就像浏览器每一帧都会有函数调用,事件循环,绘制等待;当然,人有时会因为太累而不洗澡直接睡觉,浏览器也能有限度的调整一帧内所发生的事情的顺序。
相关连接:
- [^1]: generator: https://javascript.info/generators
- [^2]: AJAX: https://developer.mozilla.org/en-US/docs/Web/Guide/AJAX
- [^3]:
XMLHttpRequest(XHR): https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest/Using_XMLHttpRequest - [^4]: Web APIs: https://developer.mozilla.org/en-US/docs/Web/API
- [^5]: https://whatwg.org/
- [^6]: https://html.spec.whatwg.org/multipage/webappapis.html#event-loops
- [^7]: https://tc39.es/ecma262/#sec-agents
- [^8]: service worker: https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API
- [^9]: worklet: https://developer.mozilla.org/en-US/docs/Web/API/Worklet
- [^10]: Event 事件:: https://www.w3schools.com/jsref/obj_event.asp
- [^11]: fetch: https://fetch.spec.whatwg.org/#concept-fetch
- [^12]: https://html.spec.whatwg.org/multipage/webappapis.html#generic-task-sources
- [^13]: 事件循环的处理模型: https://html.spec.whatwg.org/multipage/webappapis.html#event-loop-processing-model
- [^14]: https://html.spec.whatwg.org/multipage/webappapis.html#queue-a-microtask
- [^15]: https://html.spec.whatwg.org/multipage/webappapis.html#concept-task
- [^16]: 8.1.6.3 处理模型(Processing model): https://html.spec.whatwg.org/multipage/webappapis.html#event-loop-processing-model
- [^17]: https://infra.spec.whatwg.org/#implementation-defined
- [^18]: https://html.spec.whatwg.org/multipage/webappapis.html#currently-running-task
- [^19]: https://w3c.github.io/hr-time/#dfn-current-high-resolution-time
- [^20]: https://html.spec.whatwg.org/multipage/webappapis.html#concept-task-steps
- [^21]: 执行微任务检查(Perform a microtask checkpoint): https://html.spec.whatwg.org/multipage/webappapis.html#perform-a-microtask-checkpoint
- [^22]: event loop: https://html.spec.whatwg.org/multipage/webappapis.html#event-loop
- [^23]: performing a microtask checkpoint: https://html.spec.whatwg.org/multipage/webappapis.html#performing-a-microtask-checkpoint
- [^24]: event loop: https://html.spec.whatwg.org/multipage/webappapis.html#event-loop
- [^25]: performing a microtask checkpoint: https://html.spec.whatwg.org/multipage/webappapis.html#performing-a-microtask-checkpoint
- [^26]: 出列(dequeue): https://infra.spec.whatwg.org/#queue-dequeue
- [^27]: environment settings object: https://html.spec.whatwg.org/multipage/webappapis.html#environment-settings-object
- [^28]: responsible event loop: https://html.spec.whatwg.org/multipage/webappapis.html#responsible-event-loop
- [^29]: event loop: https://html.spec.whatwg.org/multipage/webappapis.html#event-loop
- [^30]: notify about rejected promises: https://html.spec.whatwg.org/multipage/webappapis.html#notify-about-rejected-promises
- [^31]: environment settings object: https://html.spec.whatwg.org/multipage/webappapis.html#environment-settings-object
- [^32]: Cleanup Indexed Database transactions: https://w3c.github.io/IndexedDB/#cleanup-indexed-database-transactions
- [^33]: ClearKeptObjects: https://tc39.es/ecma262/#sec-clear-kept-objects
- [^34]: event loop: https://html.spec.whatwg.org/multipage/webappapis.html#event-loop
- [^35]: performing a microtask checkpoint: https://html.spec.whatwg.org/multipage/webappapis.html#performing-a-microtask-checkpoint
- [^36]: #%E5%BE%AE%E4%BB%BB%E5%8B%99%E7%9A%84%E5%9F%B7%E8%A1%8C%E7%AD%96%E7%95%A5
- [^37]: current high resolution time: https://w3c.github.io/hr-time/#dfn-current-high-resolution-time
- [^38]: HRT: https://html.spec.whatwg.org/multipage/references.html#refsHRT
- [^39]: task: https://html.spec.whatwg.org/multipage/webappapis.html#concept-task
- [^40]: set: https://infra.spec.whatwg.org/#ordered-set
- [^41]: environment settings object: https://html.spec.whatwg.org/multipage/webappapis.html#environment-settings-object
- [^42]: script evaluation environment settings object set: https://html.spec.whatwg.org/multipage/webappapis.html#script-evaluation-environment-settings-object-set
- [^43]: append: https://infra.spec.whatwg.org/#set-append
- [^44]: top-level browsing context: https://html.spec.whatwg.org/multipage/browsers.html#top-level-browsing-context
- [^45]: Report long tasks: https://w3c.github.io/longtasks/#report-long-tasks
- [^46]: Chrome 开发者工具的 Performance 面板中: https://web.dev/long-tasks-devtools/
- [^47]: relevant agent: https://html.spec.whatwg.org/multipage/webappapis.html#relevant-agent
- [^48]: event loop: https://html.spec.whatwg.org/multipage/webappapis.html#concept-agent-event-loop
- [^49]: browsing context: https://html.spec.whatwg.org/multipage/browsers.html#concept-document-bc
- [^50]: container document: https://html.spec.whatwg.org/multipage/browsers.html#bc-container-document
- [^51]: browsing contexts: https://html.spec.whatwg.org/multipage/browsers.html#concept-document-bc
- [^52]: child browsing contexts: https://html.spec.whatwg.org/multipage/browsers.html#child-browsing-context
- [^53]: container documents: https://html.spec.whatwg.org/multipage/browsers.html#bc-container-document
- [^54]: shadow-including tree order: https://dom.spec.whatwg.org/#concept-shadow-including-tree-order
- [^55]: browsing context containers: https://html.spec.whatwg.org/multipage/browsers.html#browsing-context-container
- [^56]: node tree: https://dom.spec.whatwg.org/#concept-node-tree
- [^57]: 浏览上下文(browsing context): https://html.spec.whatwg.org/multipage/browsers.html#concept-document-bc
- [^58]: 充分活跃(fully active): https://html.spec.whatwg.org/multipage/browsers.html#fully-active
- [^59]: flush autofocus candidates: https://html.spec.whatwg.org/multipage/interaction.html#flush-autofocus-candidates
- [^60]: run the resize steps: https://drafts.csswg.org/cssom-view/#run-the-resize-steps
- [^61]: run the scroll steps: https://drafts.csswg.org/cssom-view/#run-the-scroll-steps
- [^62]: evaluate media queries and report changes: https://drafts.csswg.org/cssom-view/#evaluate-media-queries-and-report-changes
- [^63]: update animations and send events: https://drafts.csswg.org/web-animations/#update-animations-and-send-events
- [^64]: run the fullscreen steps: https://fullscreen.spec.whatwg.org/#run-the-fullscreen-steps
- [^65]: run the animation frame callbacks: https://html.spec.whatwg.org/multipage/imagebitmap-and-animations.html#run-the-animation-frame-callbacks
- [^66]: run the update intersection observations steps: https://w3c.github.io/IntersectionObserver/#run-the-update-intersection-observations-steps
- [^67]: mark paint timing: https://w3c.github.io/paint-timing/#mark-paint-timing
- [^68]: Intersection Observer: https://developer.mozilla.org/en-US/docs/Web/API/Intersection_Observer_API
- [^69]: FCP(First Contentful Paint): https://web.dev/first-contentful-paint/
- [^70]: start an idle period algorithm: https://w3c.github.io/requestidlecallback/#start-an-idle-period-algorithm
- [^71]: 计时器初始化步骤: https://html.spec.whatwg.org/multipage/timers-and-user-prompts.html#timer-initialisation-steps
- [^72]: WHATWG 规范文件: https://html.spec.whatwg.org/multipage/webappapis.html#perform-a-microtask-checkpoint
- [^73]: 这个链接: https://html.spec.whatwg.org/multipage/webappapis.html#perform-a-microtask-checkpoint
- [^74]: update animations and send events: https://drafts.csswg.org/web-animations/#update-animations-and-send-events
- [^75]: clean up after running script 的最后: https://html.spec.whatwg.org/multipage/webappapis.html#calling-scripts:perform-a-microtask-checkpoint
- [^76]: 调用回调的 Return 阶段的第 2 步: https://heycam.github.io/webidl/#invoke-a-callback-function
- [^77]: 这篇文章: https://jakearchibald.com/2015/tasks-microtasks-queues-and-schedules/
- [^78]:
Promise.then()便是一种 job: https://262.ecma-international.org/11.0/#sec-promise-jobs - [^79]: job 的执行时机: https://262.ecma-international.org/11.0/#sec-jobs
- [^80]:
MutationObserver: https://dom.spec.whatwg.org/#queue-a-mutation-observer-compound-microtask - [^81]:
queueMicrotask: https://html.spec.whatwg.org/multipage/timers-and-user-prompts.html#dom-queuemicrotask - [^82]:
postMessage: https://html.spec.whatwg.org/multipage/web-messaging.html#window-post-message-steps - [^83]: 但它其实是宏任务: https://html.spec.whatwg.org/multipage/web-messaging.html#window-post-message-steps
- [^84]: Chrome 开发者工具 Performance 面板的 Frames 面板: https://developer.chrome.com/docs/devtools/evaluate-performance/reference/#frames
- [^85]: 跟着 Event loop 规范理解浏览器中的异步机制: https://github.com/fi3ework/blog/issues/29
- [^86]: 从 event loop 规范探究 javaScript 异步及浏览器更新渲染时机: https://github.com/aooy/blog/issues/5
- [^87]: 深入探究 eventloop 与浏览器渲染的时序问题: https://www.404forest.com/2017/07/18/how-javascript-actually-works-eventloop-and-uirendering/
- [^88]: Tasks, microtasks, queues and schedules: https://jakearchibald.com/2015/tasks-microtasks-queues-and-schedules/
- [^89]: Loupe: http://latentflip.com/loupe/?code=JC5vbignYnV0dG9uJywgJ2NsaWNrJywgZnVuY3Rpb24gb25DbGljaygpIHsKICAgIHNldFRpbWVvdXQoZnVuY3Rpb24gdGltZXIoKSB7CiAgICAgICAgY29uc29sZS5sb2coJ1lvdSBjbGlja2VkIHRoZSBidXR0b24hJyk7ICAgIAogICAgfSwgMjAwMCk7Cn0pOwoKY29uc29sZS5sb2coIkhpISIpOwoKc2V0VGltZW91dChmdW5jdGlvbiB0aW1lb3V0KCkgewogICAgY29uc29sZS5sb2coIkNsaWNrIHRoZSBidXR0b24hIik7Cn0sIDUwMDApOwoKY29uc29sZS5sb2coIldlbGNvbWUgdG8gbG91cGUuIik7!!!PGJ1dHRvbj5DbGljayBtZSE8L2J1dHRvbj4%3D
- [^90]: WHATWG HTML Living Standard: Event loops: https://html.spec.whatwg.org/multipage/webappapis.html#event-loops
- [^91]: W3C HTML5: Event loops: https://dev.w3.org/html5/spec-LC/webappapis.html#event-loops